Motions in a video primarily consist of camera motion, induced by camera movement, and object motion, resulting from object movement. Accurate control of both camera and object motion is essential for video generation. However, existing works either mainly focus on one type of motion or do not clearly distinguish between the two, limiting their control capabilities and diversity. Therefore, this paper presents MotionCtrl, a unified and flexible motion controller for video generation designed to effectively and independently control camera and object motion. The architecture and training strategy of MotionCtrl are carefully devised, taking into account the inherent properties of camera motion, object motion, and imperfect training data. Compared to previous methods, MotionCtrl offers three main advantages: 1) It effectively and independently controls camera motion and object motion, enabling more fine-grained motion control and facilitating flexible and diverse combinations of both types of motion. 2) Its motion conditions are determined by camera poses and trajectories, which are appearance-free and minimally impact the appearance or shape of objects in generated videos. 3) It is a relatively generalizable model that can adapt to a wide array of camera poses and trajectories once trained. Extensive qualitative and quantitative experiments have been conducted to demonstrate the superiority of MotionCtrl over existing methods.
Selected Results of MotionCtrl + SVD
- Current version of MotionCtrl + SVD has the capability to guide an image-to-video generation model to create videos with both basic and complex camera motion, given a sequence of camera poses.
- You are able to generate videos with our provided Gradio Demo and [Source Code].
 |  |
|---|---|
 |  |
 |  |
Selected Results of MotionCtrl + VideoCrafter
- MotionCtrl has the capability to guide the video generation model in creating videos with complex camera motion, given a sequence of camera poses.
- MotionCtrl can guide the video generation model to produce videos with specific object motion, provided object trajectories.
- These results are generative with only one unified trained model.




Abstract
Motions in a video primarily consist of camera motion, induced by camera movement, and object motion, resulting from object movement. Accurate control of both camera and object motion is essential for video generation. However, existing works either mainly focus on one type of motion or do not clearly distinguish between the two, limiting their control capabilities and diversity. Therefore, this paper presents MotionCtrl, a unified and flexible motion controller for video generation designed to effectively and independently control camera and object motion. The architecture and training strategy of MotionCtrl are carefully devised, taking into account the inherent properties of camera motion, object motion, and imperfect training data. Compared to previous methods, MotionCtrl offers three main advantages: 1) It effectively and independently controls camera motion and object motion, enabling more fine-grained motion control and facilitating flexible and diverse combinations of both types of motion. 2) Its motion conditions are determined by camera poses and trajectories, which are appearance-free and minimally impact the appearance or shape of objects in generated videos. 3) It is a relatively generalizable model that can adapt to a wide array of camera poses and trajectories once trained. Extensive qualitative and quantitative experiments have been conducted to demonstrate the superiority of MotionCtrl over existing methods.
Methods
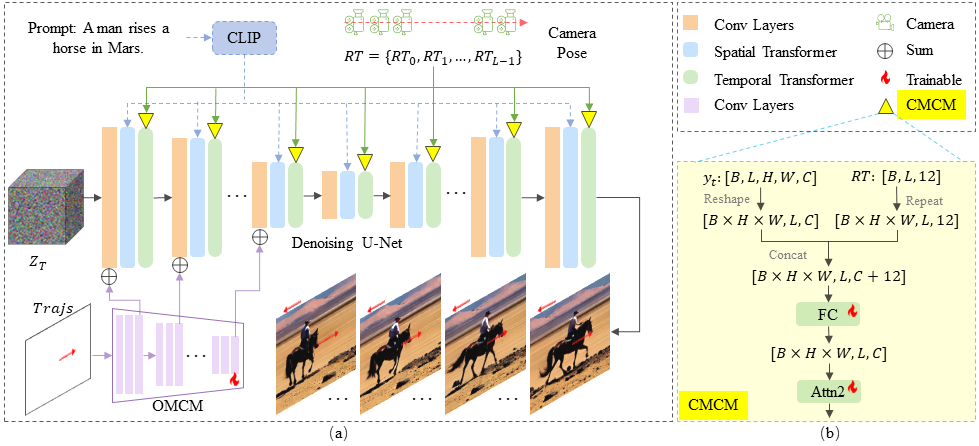
MotionCtrl extends the Denoising U-Net structure of LVDM with a Camera Motion Control Module (CMCM) and an Object Motion Control Module (OMCM). As illustrated in (b), the CMCM integrates camera pose sequences RT with LVDM’s temporal transformers by appending RT to the input of the second self-attention module and applying a tailored and lightweight fully connected layer to extract the camera pose feature for subsequent processing. The OMCM utilizes convolutional layers and downsamplings to derive multi-scale features from Trajs, which are spatially incorporated into LVDM’s convolutional layers to direct object motion. Further given a text prompt, LVDM generates videos from noise that correspond to the prompt, with background and object movements reflecting the specified camera poses and trajectories.








